A Multimodal Attention-Based Deep Learning Framework For Real-Time Activity Recognition At The Edge
Duration: November 15, 2021 – November 14, 2024
Total Award Amount: $149,900
Investigator(s): Arslan Munir (Principal Investigator)
Sponsor: Air Force Office of Scientific Research (AFOSR)
Award Abstract
Multimodal information fusion for human activity recognition is expected to outperform the models that rely on a single modality; nevertheless, most of the prior works considered either only a single or two sensor modalities. Additionally, existing approaches perform poorly under varying environmental and/or lighting conditions. Furthermore, most of the existing approaches are not suitable for real-time activity recognition.
This research project proposes a deep learning-based framework for real-time human activity recognition at the edge under varying environmental and/or lighting conditions by leveraging multiple sensor modalities (e.g., color cameras, infrared cameras, depth cameras, radars, etc.) and an attention-based mechanism to fuse sensor data. The proposed framework performs comprehensive preprocessing of raw signal data followed by a specialized individual convolutional neural network (CNN) for each modality to extract meaningful features. The proposed framework then utilizes attention-based CNNs and recurrent layers to fuse spatial and temporal features. To help enable real-time and energy-efficient human activity recognition at the edge, this project also proposes innovative algorithms and techniques for hardware acceleration of the proposed activity recognition framework. The proposed framework also performs a data-driven analysis of the probabilities of classified activities, and the role of each sensor modality in determining the output that is in turn used for resource management of sensors and the activity recognition architecture for improving the accuracy of prediction and conserving energy of edge devices.
Publications
- Hayat Ullah and Arslan Munir, “Human Action Representation Learning Using an Attention-Driven Residual 3DCNN Network”, Algorithms, vol. 16, no. 8: 369, July 2023. (Selected as Cover Article for the Journal Issue) Download
- James Wensel, Hayat Ullah, and Arslan Munir, “ViT-ReT: Vision and Recurrent Transformer Neural Networks for Human Activity Recognition in Videos”, IEEE Access, vol. 11, pp. 72227-72249, July 2023. Download
- Hayat Ullah and Arslan Munir, “Human Activity Recognition Using Cascaded Dual Attention CNN and Bi-Directional GRU Framework”, Journal of Imaging, vol. 9, no. 7: 130, June 2023. Download
- Hayat Ullah and Arslan Munir, “A 3DCNN-Based Knowledge Distillation Framework for Human Activity Recognition”, Journal of Imaging, vol. 9, no. 4: 82, April 2023. Download
Datasets
Aerial View Surveillance Dataset






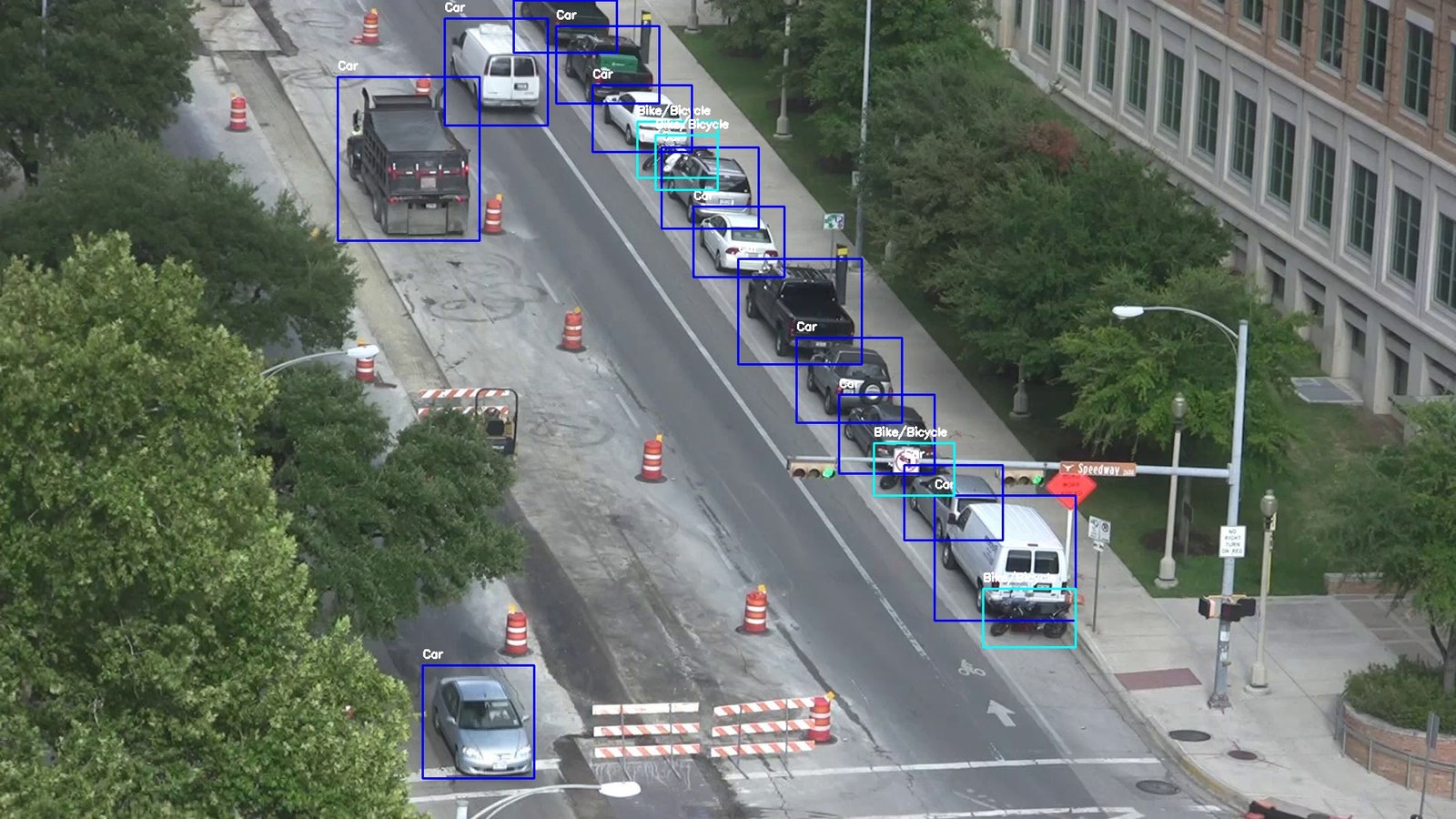


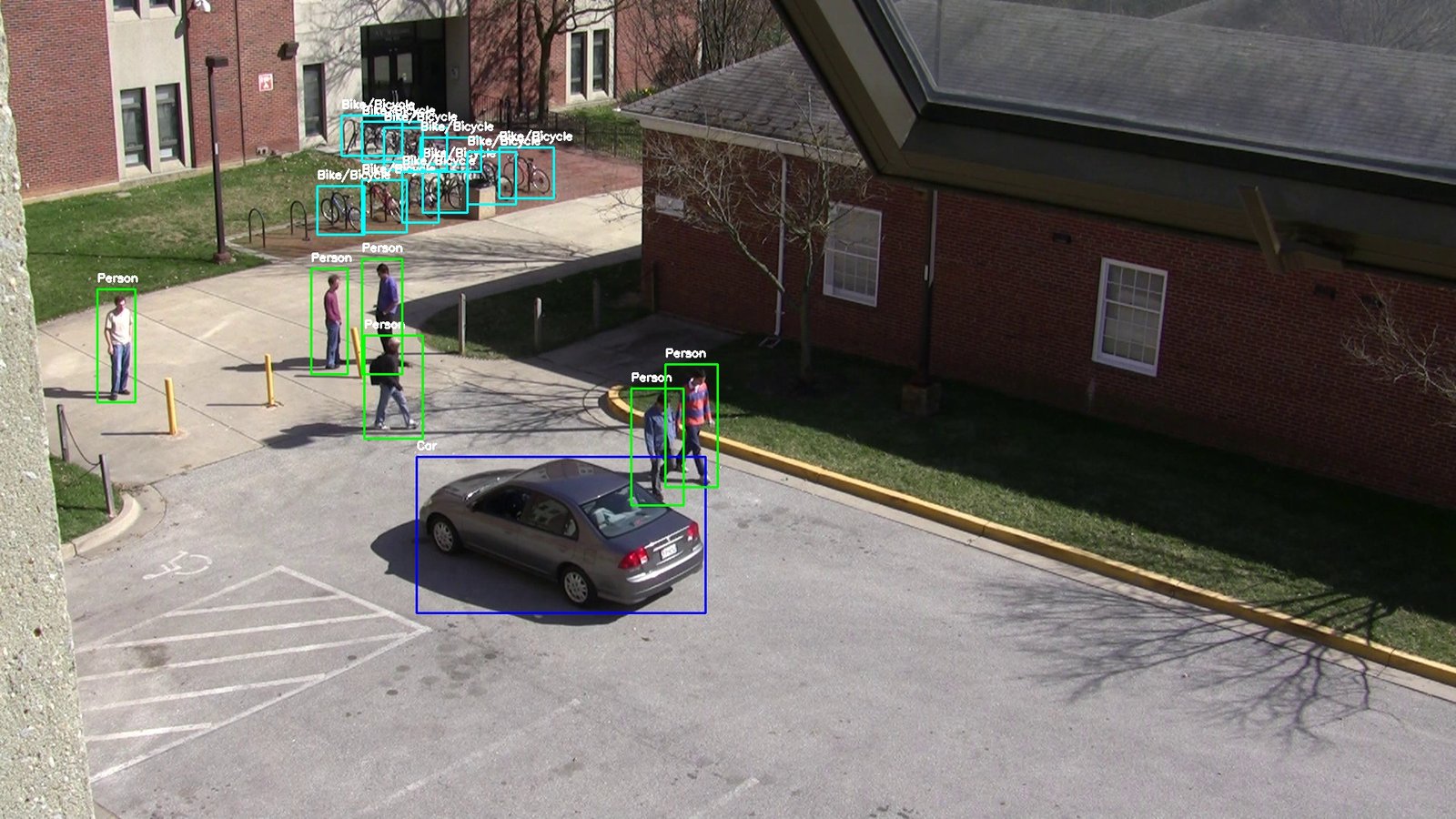
Paper: Submitted
GitHub Link: https://github.com/iscaas/AFOSR-HAR-2021-2025/tree/main/OD-VIRAT (Dataset access link will be given in GitHub)
Description: OD-VIRAT is an object detection benchmark developed purely for object detection tasks in challenging surveillance environments. This dataset is constructed from videos of the VIRAT Ground 2.0 dataset, comprising 329 surveillance videos captured through stationary ground cameras mounted at significant heights (mostly atop buildings), spanning 11 distinct scenes. The recorded scenes include construction sites, parking lots, streets, and open outdoor areas. Different models of high definition (HD) cameras are used to capture scenes at different resolutions (1920×1080 and 1280×720) and frame rates (25∼30 frames per second (FPS)).
This dataset has two distinct versions that include OD-VIRAT-Large and OD-VIRAT-Tiny dataset. The statistical details of both datasets are given below in the table.
| Dataset | Number of Scenes | Number of Videos | Number of Images | Resolution | ||||||
| Train | Validation | Test | Train | Validation | Test | Train | Validation | Test | ||
| OD-VIRAT-Large | 10 | 10 | 8 | 156 | 52 | 52 | 377686 | 137971 | 84339 | (1920×1080), (1280×720) |
| OD-VIRAT-Tiny | 10 | 10 | 8 | 156 | 52 | 52 | 12501 | 4573 | 2786 | (1920×1080), (1280×720) |
Codes
Description: OD-VIRAT is an object detection benchmark developed purely for object detection tasks in challenging surveillance environments.
- OD-VIRAT: A Large-Scale Benchmark for Object Detection in Realistic Surveillance Environments
Paper link: Submitted
GiHub link: https://github.com/iscaas/AFOSR-HAR-2021-2025/tree/main/OD-VIRAT
Description: This paper introduces two visual object detection benchmarks named OD-VIRAT Large and OD-VIRAT Tiny, aiming at advancing visual understanding tasks in surveillance imagery. The video sequences in both benchmarks cover 10 different scenes of human surveillance recorded from significant height and distance. The proposed benchmarks offer rich annotations of bounding boxes and categories, where OD-VIRAT Large has 8.7 million annotated instances in 599,996 images and OD-VIRAT Tiny has 288,901 annotated instances in 19,860 images. This work also focuses on benchmarking state-of-the-art object detection architectures, including RETMDET, YOLOX, RetinaNet, DETR, and Deformable-DETR on this object detection-specific variant of VIRAT dataset.
- A 3DCNN-Based Knowledge Distillation Framework for Human Activity Recognition
Paper link: https://www.mdpi.com/2313-433X/9/4/82
GiHub link: https://github.com/iscaas/AFOSR-HAR-2021-2025/tree/main/3DCNN-Knowledge-Distillation
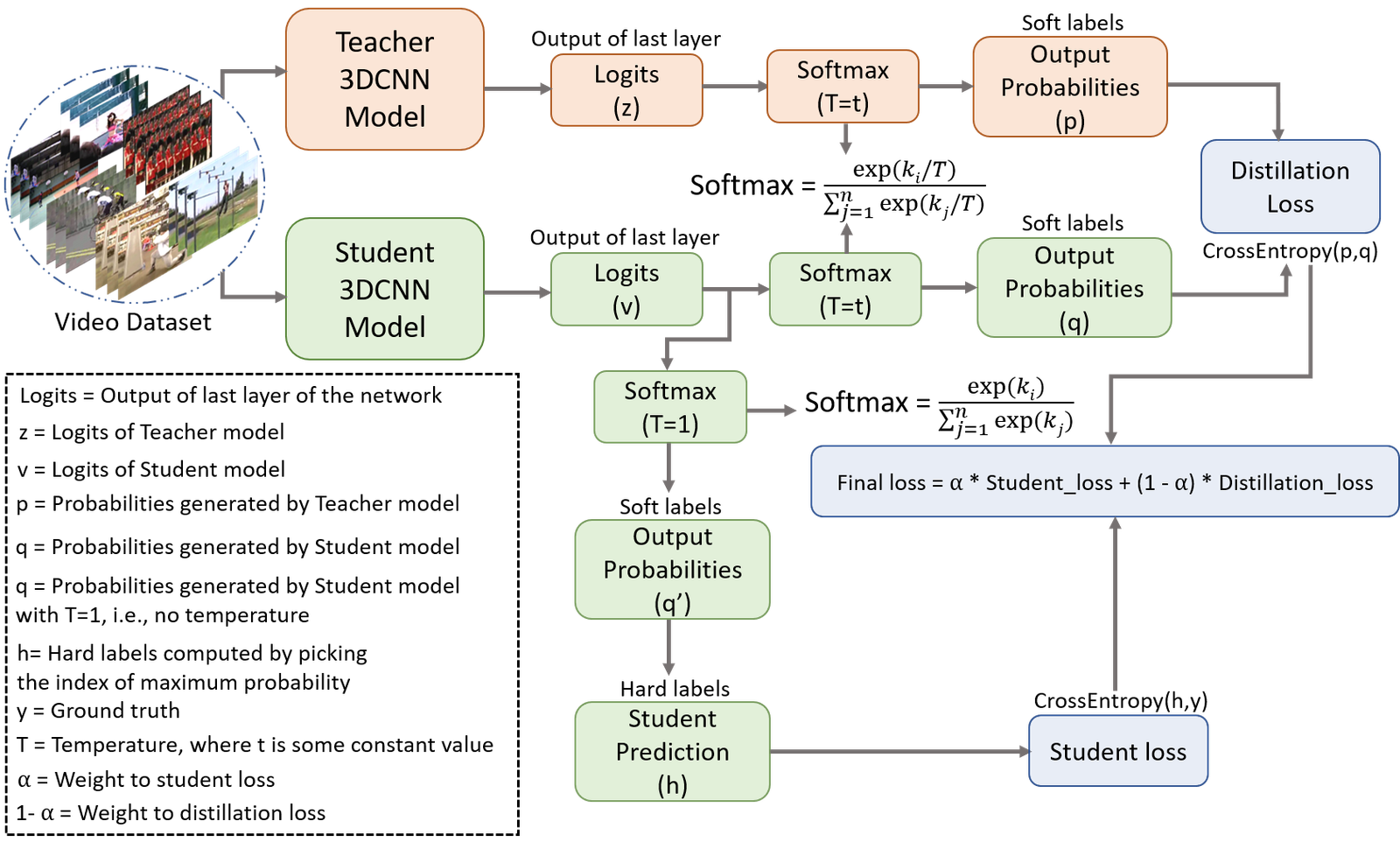
Description: In this paper, we propose a knowledge distillation framework, which distills spatio-temporal knowledge from a large teacher model to a lightweight student model using an offline knowledge distillation technique. The proposed offline knowledge distillation framework takes the predictions of two models: a large pre-trained 3DCNN teacher model and a lightweight 3DCNN student model as an input and distills the knowledge from teacher to student model. During the knowledge distillation phase, the distillation algorithm trains the student model by minimizing the difference between the teacher’s and student’s prediction, resulting in a small yet robust model that maintains the same level of precision as of teacher model.
- Human Activity Recognition Using Cascaded Dual Attention CNN And Bi-directional GRU Framework
Paper link: https://www.mdpi.com/2313-433X/9/7/130
GiHub link: https://github.com/iscaas/AFOSR-HAR-2021-2025/tree/main/DA-2DCNN
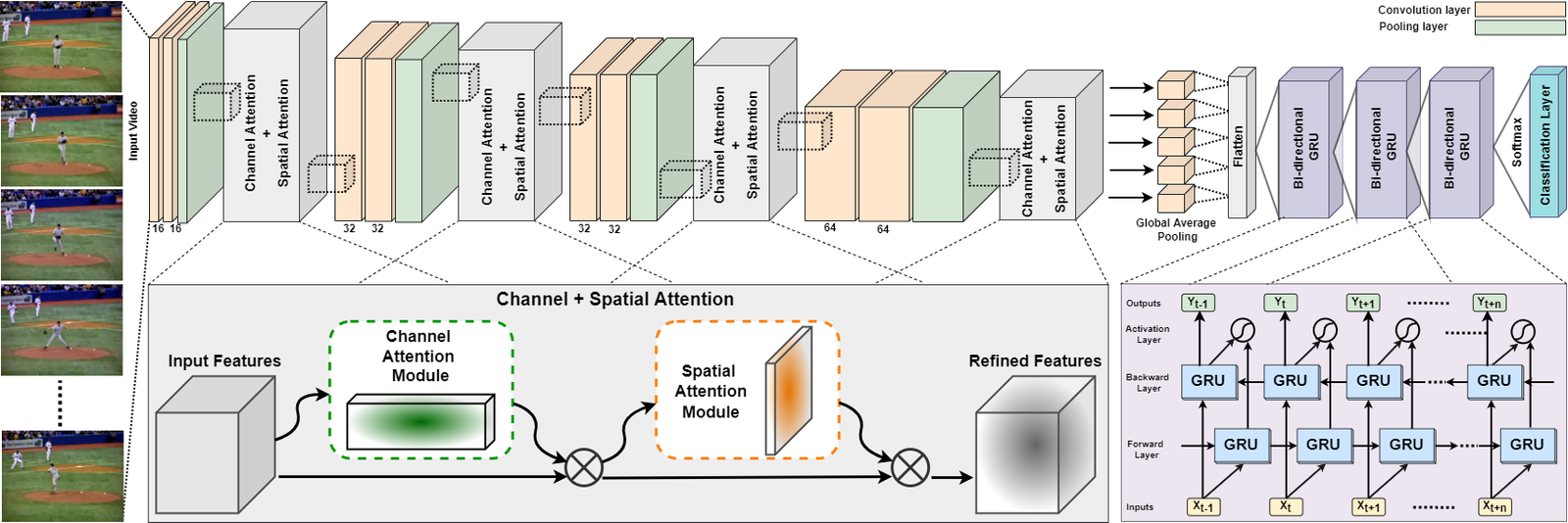
Description: This paper presents a computationally efficient yet generic spatial–temporal cascaded framework that exploits the deep discriminative spatial and temporal features for Human action recognition task. To learn robust representation of human actions from input video frames, we propose an efficient dual-attentional convolutional neural network (DA-CNN) architecture that leverages a unified channel–spatial attention mechanism to extract human-centric salient features in video frames. The dual channel–spatial attention layers together with the convolutional layers learn to be more selective in the spatial receptive fields having objects within the feature maps. The extracted discriminative salient features are then forwarded to a stacked bi-directional gated recurrent unit (Bi-GRU) for long-term temporal modeling and recognition of human actions using both forward and backward pass gradient learning.
- Human Action Representation Learning Using an Attention-Driven Residual 3DCNN Network
Paper link: https://www.mdpi.com/1999-4893/16/8/369
GiHub link: https://github.com/iscaas/AFOSR-HAR-2021-2025/tree/main/DA-Residual%203DCNN
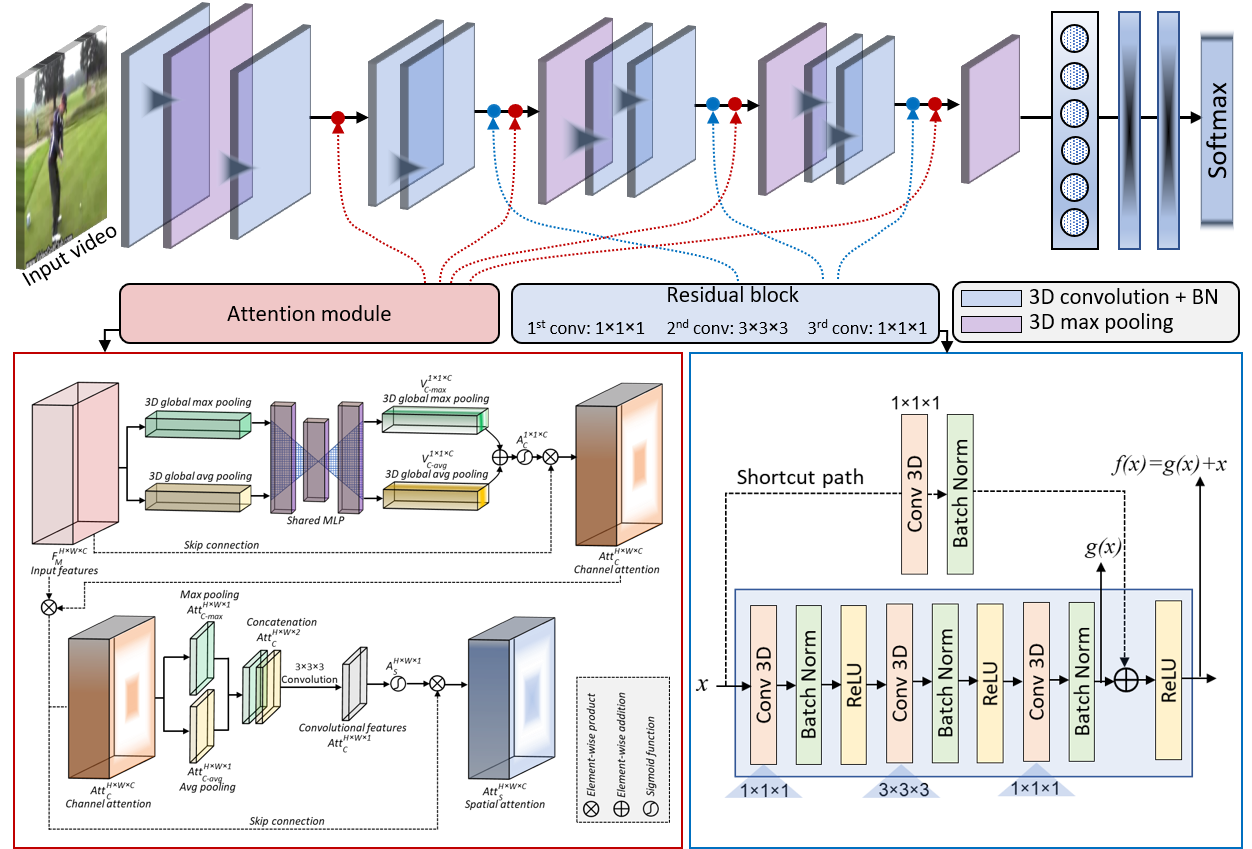
Description: In this paper, we present a computationally efficient yet robust approach, exploiting saliency-aware spatial and temporal features for human action recognition in videos. We propose an efficient approach called the dual-attentional Residual 3D Convolutional Neural Network (DA-R3DCNN). Our proposed method utilizes a unified channel-spatial attention mechanism, allowing it to efficiently extract significant human-centric features from video frames. By combining dual channel-spatial attention layers with residual 3D convolution layers, the network becomes more discerning in capturing spatial receptive field
- ViT-ReT: Vision and Recurrent Transformer Neural Networks for Human Activity Recognition in Videos
Paper link: https://ieeexplore.org/abstract/document/10177697
GiHub link: https://github.com/iscaas/AFOSR-HAR-2021-2025/tree/main/ViR-ReT
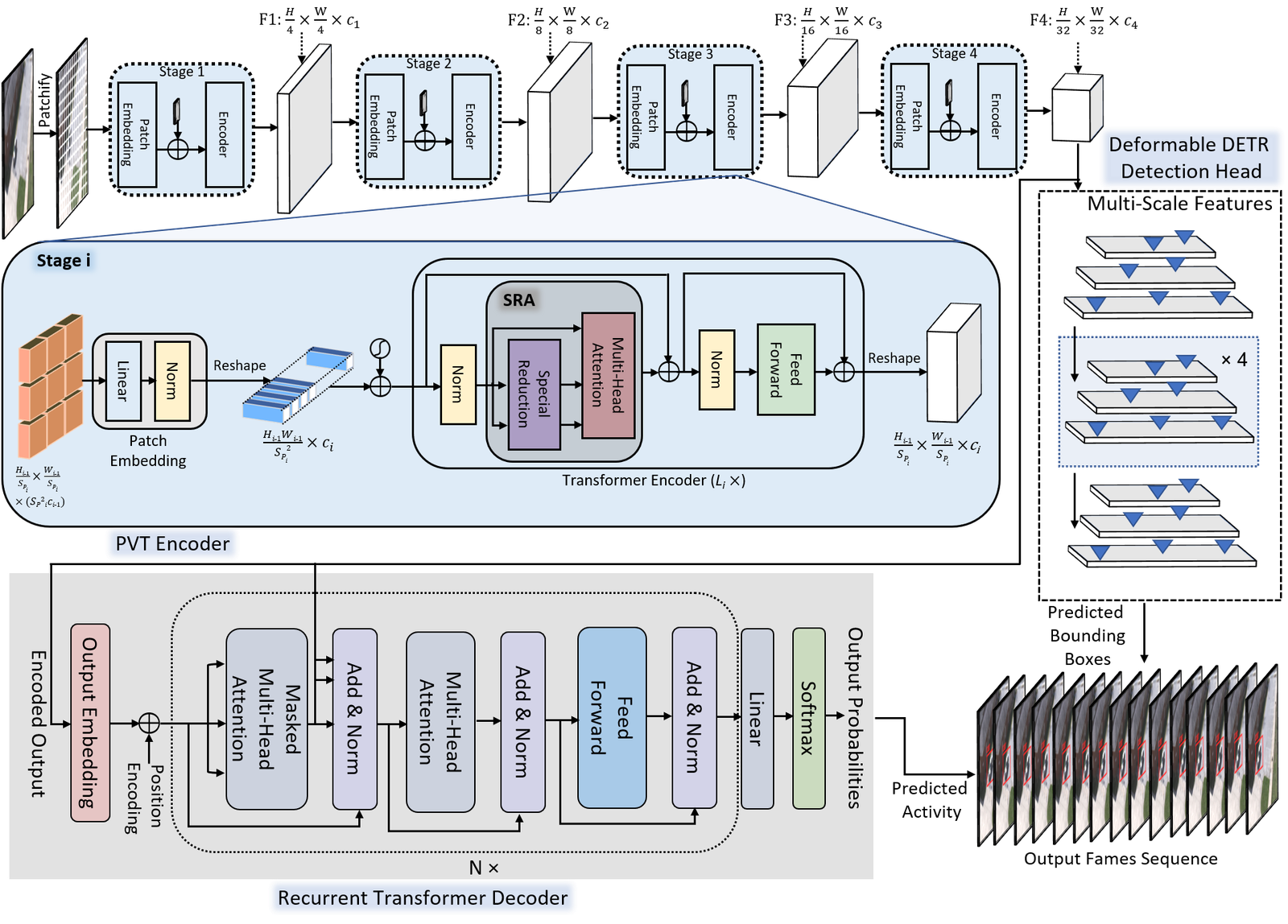
Description: This paper proposes and designs two transformer neural networks for human activity recognition: a recurrent transformer (ReT), a specialized neural network used to make predictions on sequences of data, as well as a vision transformer (ViT), a transformer optimized for extracting salient features from images, to improve speed and scalability of activity recognition. We have provided an extensive comparison of the proposed transformer neural networks with the contemporary CNN and RNN-based human activity recognition models in terms of speed and accuracy for four publicly available human action datasets.
Project Highlights